Liberating My Media Files From Wordpress
Introduction
Jekyll has lots of good importers for migrating posts from WordPress sites, but the task of bringing over your assets (files, images, etc.) is something you have to do yourself. If you plan on keeping your WordPress site running, your migrated posts will still be able to serve their assets correctly, but it’s much better to have assets fully integrated into your site, instead of being served from an external URL.
This post has instructions for one simple-ish way of getting all the files that are used in your WordPress posts. It works for Linux and should be pretty easy in OSX (you might have to install tools like wget if you don’t have that already.) Sorry Windows users–I know Jekyll is already hard for you 1. I actually run Windows, but honestly it’s easier to run Ubuntu in a VM than to get Ruby to play nice with Windows. Works well enough for me, and since I deployed the site in github pages, I can still write posts in the browser on github or push them from Windows without running jekyll serve locally. Once you have downloaded all the files, you can choose how you want to integrate them into your Jekyll site.
Setup
First, you need to migrate your posts from WordPress. There are multiple ways to do this listed on the Jekyll website for both self-hosted WordPress and WordPress.com blogs. I used exitwp since I had a WordPress.com blog and wanted to keep all my metadata.
Extracting the Assets Used in Your Posts
Start by navigating to the directory that contains all your migrated WordPress posts. You’ll need to figure out the general structure of asset links in the posts. For me, the asset links looked like this:
- [U of T Publications with Intl Coauthors](http://tallcoleman.files.wordpress.com/2014/05/u-of-t-publications-with-intl-coauthors2.png?w=625)
- [Letter from Brad Duguid](http://tallcoleman.files.wordpress.com/2014/02/signedcopy-262605.pdf)
- [Transcription of John Tory Interview](http://tallcoleman.files.wordpress.com/2013/10/transcription-of-john-tory-interview-03.docx)
Grep Asset URLs
To pull out all the asset links, I used grep, with the output streamed to a text file. In this case it looks for links that start with the asset base url and end with either ) or ?. Another way to do it would be to use a list of file extensions to find the end of each link.
grep -rio "http://tallcoleman.files.wordpress.com[^\)\?]*[\)\?]" > WpFileLinks1.txt
There were two image links ending in ‘”<’ that I missed but no big deal. In my case, there were no https links so if you have those, try “http[s]:// …” instead to catch both http:// and https:// asset links.
Processing the Grep Output
I don’t remember why I ran this command. Something to do with line breaks, I think.
sed 's/.$//' WpFileLinks1.txt > WpFileLinks2.txt
I wrote in my notes “There is a recursiveness problem which I don’t quite know how to fix.” I can’t remember what that meant, but I’ll try this all again at some point to finish writing up proper instructions. In any case, it shouldn’t prevent you from continuing on:
This command removes the file references from the grep output. I’m sure there must be a better way of doing this, but this (mostly) worked for me:
sed 's|.*:h\(.*\)|\1|' WpFileLinks2.txt > WpFileLinks3.txt
I had to go add the h’s back in using find-and-replace to substitute ‘ttp://’ with ‘http://’. (I told you it’s not a very good method). I should go learn the proper syntax for sed later.
Downloading Your Files
And now the magic happens:
wget -i ~/Documents/tallcoleman.github.io/WpFileLinks3.txt
the -i flag tells wget to get the list of URLs from our file.
Nice folder of files!
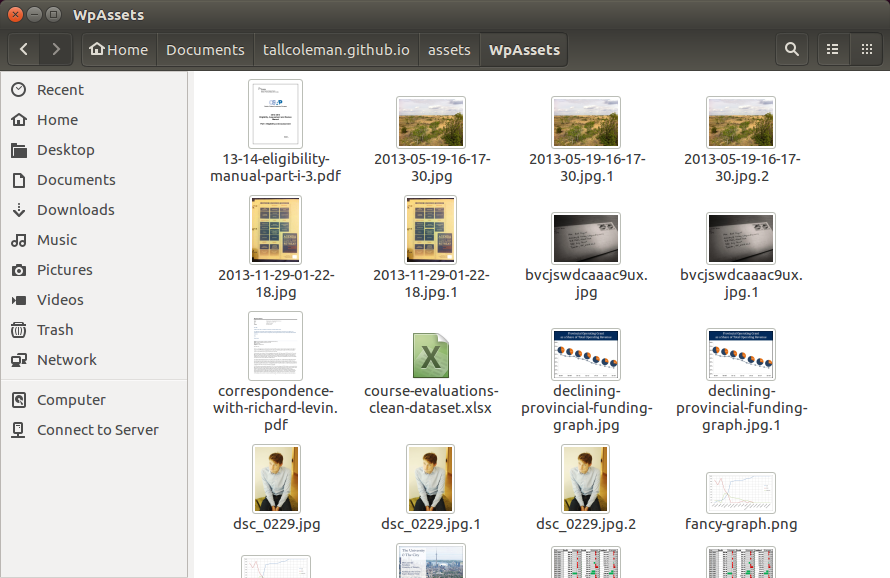
I’ll have to decide later if I want to fully integrate them with my separated assets folder, or just keep them in the same folder to make swapping out the links easier.
Final Step: Swap Out the Asset Links in Your Imported WordPress Posts
What worked for me so far was doing find and replace using regex in Atom:
Find:
http://tallcoleman.files.wordpress.com/[0-9]{4}/[0-9]{2}/
Replace:
/assets/WpAssets/
There are still some php suffixes remaining but Jekyll just ignores them, so I’ve only removed them if I catch them in the wild, though finding them with regex shouldn’t be too hard if you want to make sure you’ve removed them all.
If you have suggestions for ways I can do this less badly, hit me up at ben[dot]coleman[at]mail[dot]utoronto[dot]ca or on Twitter.